Big Data in Healthcare: Use Cases, Benefits, and Challenges You Need to Know (2026)
Big data in healthcare is the practice of aggregating clinical records, diagnostic images, lab results, wearable readings, insurance claims, and genomic sequences into a unified analytical environment and then using that combined dataset to answer questions no single system can answer on its own.
The scale is difficult to overstate. A single hospital generates roughly 50 petabytes of data per year (IDC), and roughly 80% of it is unstructured, locked inside clinical notes, radiology images, and handwritten records that traditional BI tools cannot process (IBM). McKinsey estimates that system-wide adoption of big data analytics could save US healthcare $300 to $450 billion annually (McKinsey). The data exists. The ability to use it usually does not, and the gap is rarely the analytics platform. In the healthcare data projects we deliver at Savvycom, the blocker is almost always the state of the data itself: unstructured, scattered across systems, and inconsistently coded. Fix that first and the analytics follow. Skip it and the most expensive platform on the market still produces unreliable dashboards.
This guide covers which use cases deliver production-grade results, how data platforms compare, where compliance applies specifically at the analytical layer, and what mistakes to avoid. For a broader context on healthcare technology, see the guide on healthcare software development.
1. What is big data in healthcare, and what defines its scale?
“Big data” in healthcare refers to datasets too large, too fast-moving, or too varied for traditional database tools to process, defined by five characteristics known as the 5 Vs: volume, velocity, variety, veracity, and value.
Each V creates a specific engineering challenge that shapes how the data platform must be designed:
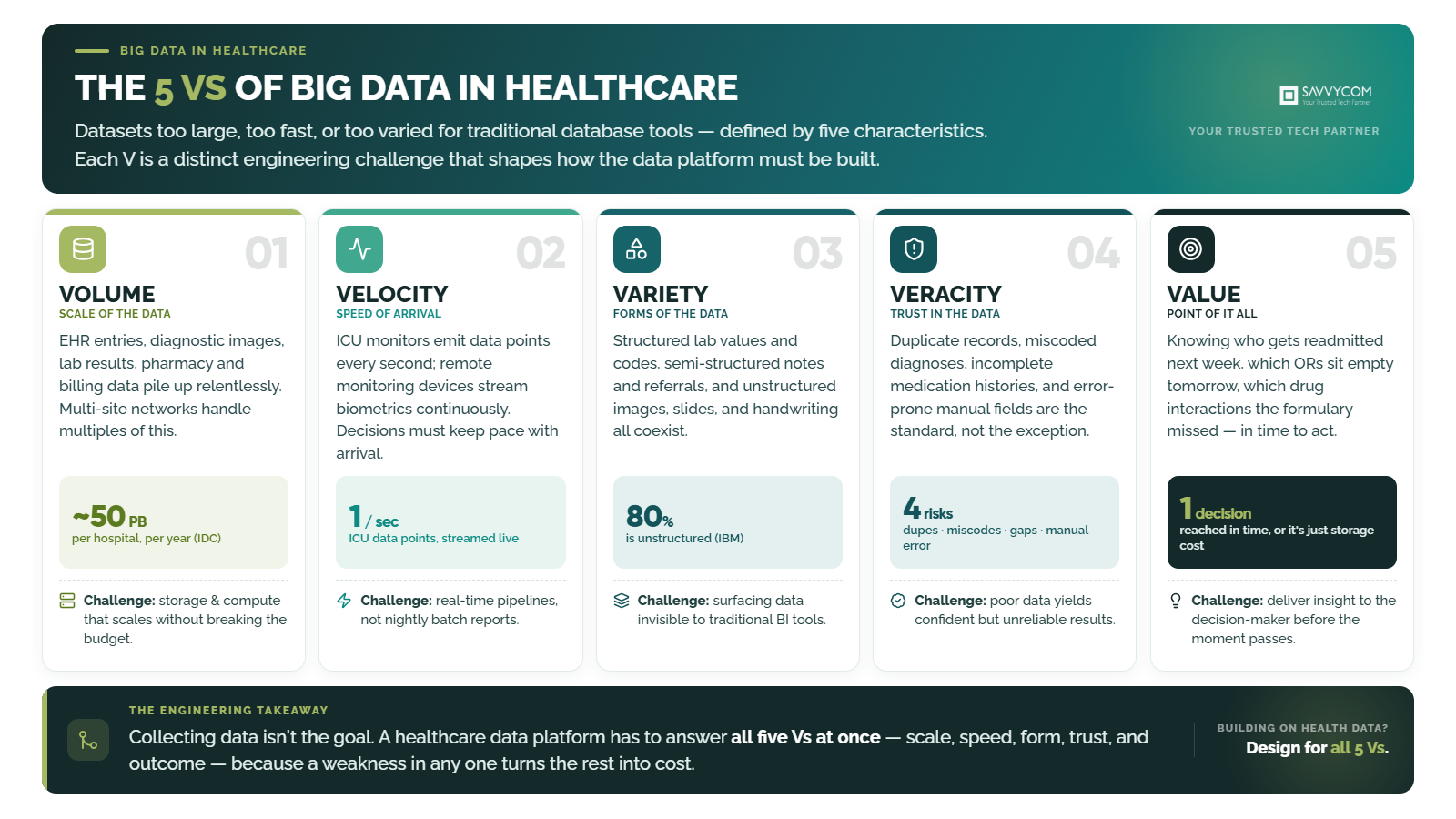 2. Use cases delivering measurable value in production
2. Use cases delivering measurable value in production
Six categories of big data use cases are generating documented ROI in healthcare in 2026: clinical predictive analytics, population health, operational optimization, drug development, fraud detection, and precision medicine.
Clinical predictive analytics
Hospitals feed real-time EHR data, vital signs, lab results, and medication history into models that predict sepsis onset, readmission risk, and patient deterioration 4 to 12 hours before traditional clinical signs appear. Published studies document 20–30% reductions in sepsis mortality at hospitals deploying these models. The difference between a 6-hour head start and no warning changes the intervention from reactive to preventive.
Population health management
Payers and health systems analyze claims, clinical, and social determinant data across large patient populations to identify the 5% of patients who will account for 50% of next year’s costs. Allocating preventive resources before those costs materialize is where McKinsey estimates a substantial share of the $300–$450 billion savings potential lives.
Operational resource optimization
A hospital running at 1–3% margins cannot afford an empty OR or an overstaffed night shift. Predictive models forecast tomorrow’s admissions well enough to adjust bed allocation and staffing today, and cleaning up scheduling data removes the operational friction that quietly drains margin. Savvycom saw this directly on a surgery booking platform we built for PECTUS, a U.S. Pectus Excavatum surgery provider: manual, fragmented scheduling and intake were creating administrative bottlenecks and patient drop-off between consultation and surgery. Digitizing the end-to-end booking and patient-management workflow closed those gaps and tightened care coordination. For providers running thin, that operational drag is the line between viable and not.
Drug discovery and real-world evidence
Pharmaceutical companies use genomic data, real-world evidence, and clinical trial datasets to identify drug candidates faster and design trials with better-matched cohorts. McKinsey estimates AI and big data could compress drug development timelines by 30–50% (McKinsey). Insilico Medicine brought an AI-discovered drug candidate from initial identification to Phase II trials in under 30 months, a process that typically takes 4 to 6 years.
Fraud detection and claims integrity
Healthcare fraud costs the US system an estimated $100 billion annually (FBI). Analytics platforms flag anomalous billing patterns, duplicate claims, and provider behavior that deviates from established norms, catching patterns too complex or too novel for predefined rules. The ROI case for automated detection is straightforward: even a 1% improvement in fraud capture recovers hundreds of millions.
Precision medicine and genomic analytics
Combining genomic data with clinical outcomes allows providers to match treatments to individual patient profiles rather than population averages. This is most advanced in oncology, where tumor genomics now informs treatment selection in a growing percentage of cancer cases. WHO recognizes precision medicine as a priority area where data-driven approaches are poised to transform care delivery.
3. Healthcare data platform comparison: which infrastructure fits your use case?
Production healthcare data platforms in 2026 follow one of two architectural patterns: data lakehouse for ML-heavy unstructured workloads or FHIR-native stores for interoperability-first environments, with five major platforms competing for enterprise healthcare analytics.
Data lakehouse vs FHIR-native store
A data lakehouse (Databricks, Snowflake) combines storage and compute in a single layer, handling structured tables and unstructured imaging data in the same environment. It suits organizations doing heavy ML training on clinical images or NLP on clinical notes. A FHIR-native store (AWS HealthLake, Azure Health Data Services) is optimized for interoperability; it ingests, normalizes, and serves data in FHIR R4 format, making it the better choice when the primary requirement is data exchange across systems rather than ML workloads.
Five-platform comparison
| Platform | HIPAA-eligible | FHIR native | Real-time ingestion | Best for | Pricing model |
| AWS HealthLake | Yes (BAA required) | Yes, FHIR R4 native | Via Kinesis + Lambda | FHIR-first orgs on AWS |
Per stored/queried data
|
| Azure Health Data Services | Yes (BAA required) | Yes, FHIR + DICOM + MedTech IoT | Via Event Hubs | Multi-modal data (imaging + clinical) |
Per API transaction
|
| Google Cloud Healthcare API | Yes (BAA required) | Yes, FHIR R4 | Via Pub/Sub | BigQuery integration for large analytics |
Per API call + storage
|
| Snowflake Healthcare | Yes (BAA required) | Via FHIR connector | Limited batch | Cross-org data sharing |
Compute + storage separated
|
| Databricks Lakehouse | Yes (BAA required) | Via partner connectors | Yes, Delta Live Tables | ML on unstructured (imaging, notes) |
Compute-based (DBU)
|
Healthcare data standards that matter
Three standards define how data moves between systems and into analytics layers in 2026:
- FHIR R4 (HL7): The interoperability standard for clinical data exchange. This standard is effectively mandatory for new healthcare integrations in most regulated markets. FHIR Bulk Data Access extends this to population-level analytics.
- OMOP CDM (OHDSI): The Observational Medical Outcomes Partnership. The Common Data Model standardizes clinical data for observational research across institutions. Increasingly used as the analytical layer standard for multi-site health networks running population health analytics.
- DICOM: The standard for medical imaging data. Any analytics platform processing radiology, pathology, or cardiology images must ingest and query DICOM natively or through a certified connector.
4. Data governance and compliance at the analytical layer
Big data compliance in healthcare operates at the analytical layer, not the application layer. The regulatory frameworks themselves (HIPAA, GDPR, PDPA, APPI) are covered in detail in the healthcare software development guide. What matters specifically for big data is how those frameworks apply to aggregated, de-identified analytical datasets.
De-identification at the analytical scale
HIPAA’s Safe Harbor method lists 18 identifiers that must be stripped before data can be used for analytics without individual consent. That works for individual records. It breaks down when datasets are large enough for re-identification attacks; a combination of age, zip code, and diagnosis date can uniquely identify a patient in a small population. k-anonymity and differential privacy are the two approaches gaining traction: k-anonymity ensures every record is indistinguishable from at least k-1 others, and differential privacy adds calibrated noise to query results so individual records cannot be reverse engineered.
Cross-border data residency for multi-site analytics
A health network running analytics across facilities in the US, Japan, and Singapore cannot store all data in one region. APPI (Japan) restricts cross-border transfers unless the recipient country has equivalent protections. The PDPA (Singapore, Thailand) requires either consent or certified transfer mechanisms. This is an architecture decision that must be resolved before any data pipeline is built, not a policy question to address after deployment. This is operational reality for us, not theory: Savvycom delivers healthcare builds across the US and APAC, including Vietnam, where we built the Jio Health telemedicine platform, and residency and consent rules diverge market to market.
Purpose limitation for analytical datasets
GDPR’s purpose limitation principle (Article 5(1)(b)) means data collected for clinical care cannot automatically be used for operational analytics without separate consent or a documented legitimate interest basis. Most healthcare organizations have not mapped this properly. The result: analytics teams build dashboards on data they may not legally be using for that purpose. The compliance exposure grows with every additional use case added to the data platform. Healthcare breaches cost $9.77 million on average in 2024 (IBM, 2024), and the breach does not need to involve a hack. Unauthorized analytical use of PHI is itself a compliance violation.
5. Common failure modes in healthcare big data projects
The three most expensive mistakes in healthcare big data projects are ingesting data before defining use cases, treating data quality as an IT problem, and selecting a platform before auditing what the organization actually has.
6. Why data readiness, not model quality, decides whether healthcare AI works
The barrier to healthcare AI is almost never the model. It is whether the underlying data is clean, structured, and reachable. A capable model trained on messy, scattered data produces a convincing demo and no clinical value.
We learned this on a document intelligence platform Savvycom built for a U.S. healthcare operation. The model was the easy part. The hard part was the data: patient and billing records arrived as printed forms, structured exports, and handwritten clinical notes, and each format broke automation in a different way. Once the pipeline could extract and validate across all three, with low-confidence cases routed to a human reviewer before anything reached a downstream system, manual data entry dropped 50 to 70% and data accuracy improved 30 to 50%. None of that came from a better algorithm. It came from getting the data ready.
Clinical data usually sits scattered across EHR systems, lab tools, imaging platforms, billing software, spreadsheets, and manual notes. When that data is incomplete, inconsistent, or hard to extract, even a strong model creates zero value in a live clinical or operational workflow.
Before expecting measurable results from healthcare AI, enterprise technical teams should validate four things:
- Data readiness: Is the data structured, clean, normalized, and reachable for this specific use case, not the data lake in general?
- Workflow fit: Can clinicians act on an AI alert inside the tools they already use, without switching tabs or breaking their routine?
- Compliance design: Are immutable audit logs, role-based access, encryption, and consent handling built into the pipeline from the start rather than added before launch?
- Human review: Who is accountable for approving, rejecting, or overriding an AI recommendation, and is that person in the loop by design?
Judge a healthcare AI system by whether it can safely support a real decision inside a clinical, operational, or administrative workflow. Not by its accuracy score on a slide.
7. Building the capability: a sequenced approach
Healthcare big data capability is built in five sequential steps: data audit, governance framework, platform selection matched to use cases, pilot deployment, and talent strategy.
- Step 1 — Data audit and source inventory: Catalogue every data source: EHR systems, lab platforms, imaging archives, claims databases, wearable feeds. Document formats, update frequencies, quality levels, and access permissions. This inventory determines the scope and cost of everything that follows.
- Step 2 — Governance framework before analytics: Define ownership, quality standards, access policies, and retention rules before building anything. Assign data stewards by domain (clinical, financial, operational). Governance is not a policy document, it is an operational process that runs continuously.
- Step 3 — Platform selection matched to use cases: Use the comparison in Section 3 to match your primary workload to the right platform. FHIR-native for interoperability-first. Lakehouse for ML-heavy workloads. Do not select a platform before completing Steps 1 and 2.
- Step 4 — Pilot on 2 to 3 data-ready, high-impact use cases: Select use cases based on data readiness and business impact, not technical interest. A readmission prediction model that pays for itself inside the first year is a better starting point than a genomic analytics platform that needs 18 months of data preparation before its first output.
- Step 5 — Talent strategy: build, buy, or partner: Assess whether the organization can hire data science, engineering, and clinical informatics talent internally. Most organizations use a hybrid model: external partners for architecture and initial deployment and internal teams for ongoing operation.
8. Frequently asked questions
What are the biggest problems with big data in healthcare?
The five most cited problems are data privacy compliance (HIPAA/GDPR breaches cost $9.77M on average per IBM 2024), data quality and standardization across legacy systems, system integration complexity across HL7 v2 and FHIR R4 environments, cost justification for systemic benefits that are hard to attribute, and a shortage of talent who understand both data science and clinical workflows.
What are the characteristics of big data in healthcare?
Healthcare big data is distinguished from general big data by three characteristics: the data is regulated (PHI under HIPAA, GDPR, and PDPA); the stakes of analytical errors are clinical (wrong predictions can affect patient safety); and the integration surface is unusually complex (dozens of legacy systems with incompatible standards). These characteristics mean healthcare big data platforms carry compliance, validation, and integration obligations that general-purpose analytics platforms do not.
What is an example of healthcare data used in analytics?
A hospital uses five years of EHR admission records, vital signs, lab results, medication history, and diagnosis codes to train a model that predicts which patients admitted through the emergency department will develop sepsis within the next 12 hours. The model runs on real-time data and sends alerts to the clinical team before traditional signs appear. Hospitals deploying these models have documented 20 to 30% reductions in sepsis mortality in published clinical studies.
What is the impact of big data in healthcare?
McKinsey estimates system-wide big data adoption could save US healthcare $300 to $450 billion annually through reduced readmissions, optimized operations, fraud prevention, and precision medicine. Individual health systems report 10 to 15% reductions in operational costs after deploying analytics. In drug development, big data and AI are compressing timelines by 30 to 50% (McKinsey). The financial impact is documented. The challenge is building the infrastructure to capture it.
Looking for a Trusted Tech Partner That Delivers Your Measurable Values?
Savvycom builds healthcare data platforms and analytics pipelines for hospitals, health networks, and digital health companies across APAC, Japan, South Korea, Australia, and the US, built to local compliance standards from day one.
Explore the engagement model: Healthcare IT Solutions

